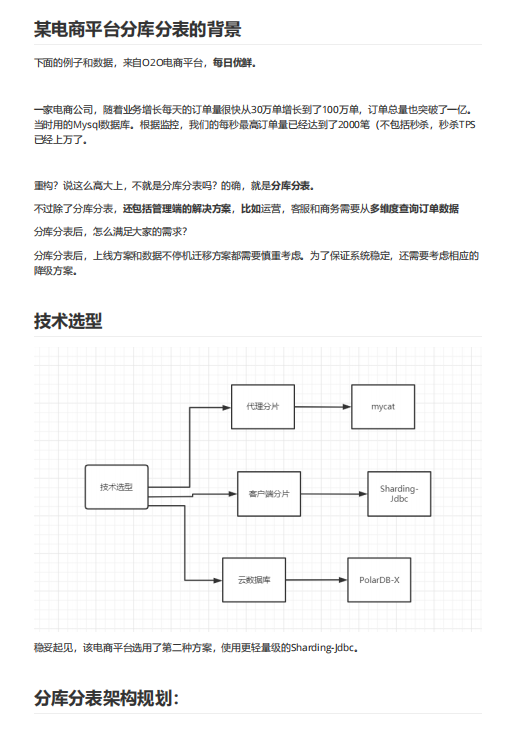
资料内容:
一家电商公司,随着业务增长每天的订单量很快从30万单增长到了100万单,订单总量也突破了一亿。
当时用的Mysql数据库。根据监控,我们的每秒最高订单量已经达到了2000笔(不包括秒杀,秒杀TPS
已经上万了。
重构?说这么高大上,不就是分库分表吗?的确,就是分库分表。
不过除了分库分表,还包括管理端的解决方案,比如运营,客服和商务需要从多维度查询订单数据
分库分表后,怎么满足大家的需求?
分库分表后,上线方案和数据不停机迁移方案都需要慎重考虑。为了保证系统稳定,还需要考虑相应的
降级方案。
分库分表架构规划:
目标: 我们希望经过本次重构,系统能支撑两年,两年内不再大改。业务方预期: 两年内日单量达到1000万。相当于两年后日订单量要翻10倍。
悲观的预估
根据上面的数据,我们分成了16个数据库,每个库分了16张表,按user_id做hash。
即便按照每天1000万的订单量规划,两年总单量是73亿, 每个库的数据量平均是4.56亿(4.56亿=73
亿/16),,每张表的数据量平均是2850万(2850万=4.56亿/16),虽然有点超出了1000W的建议值,但
是这是按照两年之后理想的值做的预估。实际没有那么多。
乐观的预估
即便按照每天100万的订单量规划,两年总单量是7.3亿, 每个库的数据量平均是0.456亿(0.456亿=7.3
亿/16),每张表的数据量平均是285万(285万=0.456亿/16)。
分库分表主要是为了APP 用户端下单和查询使用,按user_id的查询频率最高,其次是order_id。所以
我们选择user_id做为sharding column,按user_id做hash,将相同用户的订单数据存储到同一个数
据库的同一张表中。这样用户在网页或者App上查询订单时只需要路由到一张表就可以获取用户的所有
订单了,这样就保证了查询性能。

