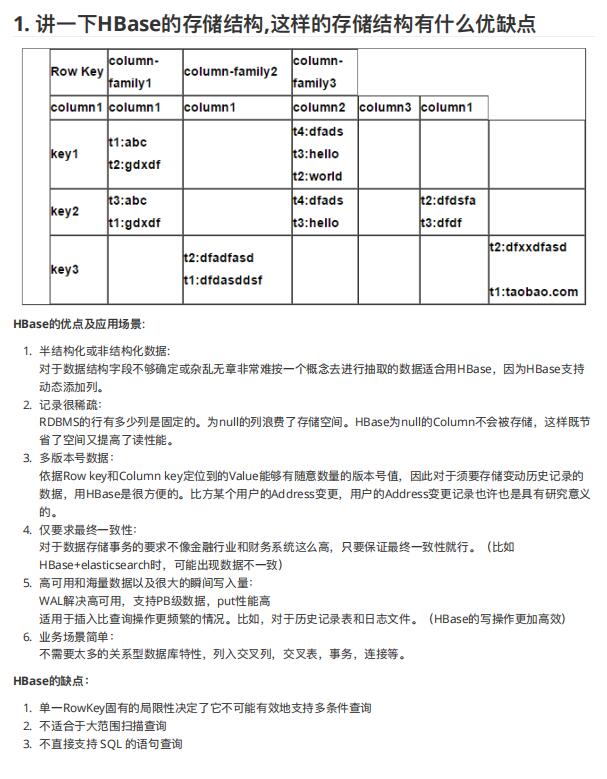
资料内容:
HBase的优点及应⽤场景:
1. 半结构化或⾮结构化数据:
对于数据结构字段不够确定或杂乱⽆章⾮常难按⼀个概念去进⾏抽取的数据适合⽤HBase,因为HBase⽀持
动态添加列。
2. 记录很稀疏:
RDBMS的⾏有多少列是固定的。为null的列浪费了存储空间。HBase为null的Column不会被存储,这样既节
省了空间⼜提⾼了读性能。
3. 多版本号数据:
依据Row key和Column key定位到的Value能够有随意数量的版本号值,因此对于须要存储变动历史记录的
数据,⽤HBase是很⽅便的。⽐⽅某个⽤户的Address变更,⽤户的Address变更记录也许也是具有研究意义
的。
4. 仅要求最终⼀致性:
对于数据存储事务的要求不像⾦融⾏业和财务系统这么⾼,只要保证最终⼀致性就⾏。(⽐如
HBase+elasticsearch时,可能出现数据不⼀致)
5. ⾼可⽤和海量数据以及很⼤的瞬间写⼊量:
WAL解决⾼可⽤,⽀持PB级数据,put性能⾼
适⽤于插⼊⽐查询操作更频繁的情况。⽐如,对于历史记录表和⽇志⽂件。(HBase的写操作更加⾼效)
6. 业务场景简单:
不需要太多的关系型数据库特性,列⼊交叉列,交叉表,事务,连接等。
HBase的缺点:
1. 单⼀RowKey固有的局限性决定了它不可能有效地⽀持多条件查询
2. 不适合于⼤范围扫描查询
3. 不直接⽀持 SQL 的语句查询
2. 讲⼀下HBase的写数据的流程1. Client先访问zookeeper,从.META.表获取相应region信息,然后从meta表获取相应region信息
2. 根据namespace、表名和rowkey根据meta表的数据找到写⼊数据对应的region信息
3. 找到对应的regionserver 把数据先写到WAL中,即HLog,然后写到MemStore上
4. MemStore达到设置的阈值后则把数据刷成⼀个磁盘上的StoreFile⽂件。
5. 当多个StoreFile⽂件达到⼀定的⼤⼩后(这个可以称之为⼩合并,合并数据可以进⾏设置,必须⼤于等于2,
⼩于10——hbase.hstore.compaction.max和hbase.hstore.compactionThreshold,默认为10和3),会触发
Compact合并操作,合并为⼀个StoreFile,(这⾥同时进⾏版本的合并和数据删除。)
6. 当Storefile⼤⼩超过⼀定阈值后,会把当前的Region分割为两个(Split)【可称之为⼤合并,该阈值通过
hbase.hregion.max.filesize设置,默认为10G】,并由Hmaster分配到相应的HRegionServer,实现负载均
衡
3. 讲⼀下HBase读数据的流程
1. ⾸先,客户端需要获知其想要读取的信息的Region的位置,这个时候,Client访问hbase上数据时并不需要
Hmaster参与(HMaster仅仅维护着table和Region的元数据信息,负载很低),只需要访问zookeeper,从
meta表获取相应region信息(地址和端⼝等)。【Client请求ZK获取.META.所在的RegionServer的地址。】
2. 客户端会将该保存着RegionServer的位置信息的元数据表.META.进⾏缓存。然后在表中确定待检索rowkey所
在的RegionServer信息(得到持有对应⾏键的.META表的服务器名)。【获取访问数据所在的RegionServer
地址】
3. 根据数据所在RegionServer的访问信息,客户端会向该RegionServer发送真正的数据读取请求。服务器端接
收到该请求之后需要进⾏复杂的处理。
4. 先从MemStore找数据,如果没有,再到StoreFile上读(为了读取的效率)。

